
Anyo Labs Molecular Generator
Importance and Limitations of Generative AI
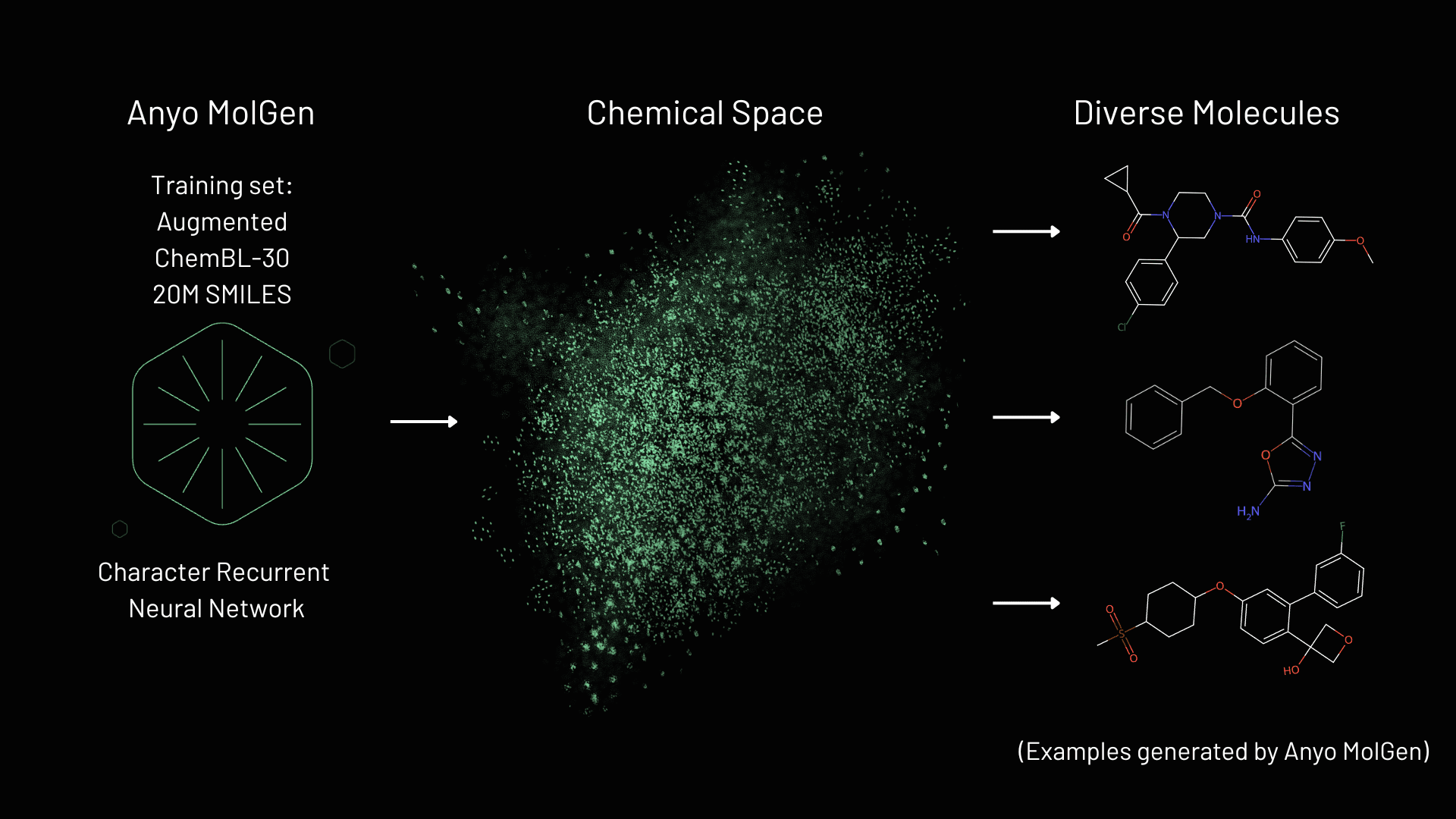
Anyo Labs molecular generator (MolGen) is an advanced generative AI engine designed to advance pre-clinical drug discovery by generating novel, synthesizable small molecules represented as SMILES strings. the tool leverages computational methods to create diverse molecular libraries from scratch, bypassing the limitations of existing static libraries limited in terms of size, and possibly diversity. At the tools core is a character recurrent neural network (RNN) enabling it to probe the vast chemical space of drug-like molecules[1]. The potential space vastly exceeds traditional databases like GDB-17, which contains 166 billion molecules [2]. By generating tailored, diverse molecules, generative AI offers a dynamic alternative to screening before labor-intensive synthesis and testing, accelerating the discovery of lead candidates.
Generative AI in drug discovery today
Generative AI is critical for drug discovery, as it enables the rapid proposal of novel compounds to address unmet medical needs, potentially yielding treatments for complex diseases. By automating molecule design, it reduces the time and cost of synthesizing and testing millions of compounds, streamlining pharmaceutical innovation [3]. However, existing generative AI models face significant limitations. Most, such as those based on variational autoencoders (VAEs) or generative adversarial networks (GANs), generate modest libraries of 10^4 to 10^7 molecules at a time with limitations in structural diversity [4,5]. For instance, VAE models or those benchmarked in MOSES (trained on ZINC’s ~220,000 molecules) tend to overfit to their training distributions, producing redundant or similar structures [4,6]. Additionally, slow generation speeds hinder efficient exploration of chemical space, constraining the discovery of unique lead candidates [4,7]. These limitations underscore the need for scalable, efficient AI models capable of producing larger, more diverse libraries.
Anyo Labs drug discovery pipeline
The combination of Anyo MolGen with the Scoring method [8], encompasses a proprietary method that enhances computational efficiency and scalability in molecular generation:
- High Validity:Anyo MolGen generates 95.4% valid molecules, ensuring high-quality outputs.
- Near-Perfect Uniqueness: Over 99.8% of generated compounds are unique, minimizing redundancy across large-scale generation.
- Exceptional Speed: Anyo MolGen generates approximately 5,000 SMILES per second on a single NVIDIA A100 node, significantly outpacing many competing models [4,7].
The Scoring method, detailed in our 2025 study [8], optimizes for both accuracy and computational efficiency, in combination with Anyo MolGen allows the user to explore relevant parts of the chemical space as it is being generated. A seed-free approach and high throughput enable it to explore vast, diverse chemical spaces, making it ideal for early-stage drug discovery. This efficiency sets Anyo MolGen apart from competitors limited by smaller library sizes and diversity, positioning it as a scalable solution for navigating the vast chemical space.
Real-World Validation: Internal Project Success
The capabilities were validated in an internal hit identification project where hundreds of millions of novel compounds where designed, 200 compounds were selected for synthetic evaluation based on their inhibitory potential. Remarkably, all 200 were deemed synthesizable at first glance, with 150 classified as unproblematic for synthesis. Anyo then synthesized 32 novel compounds of which all were successful and delivered for experimental testing. This high success rate for synthetic feasibility demonstrates it's ability to produce practical, high-quality molecules suitable for laboratory development. The project highlights a key advantage: MolGen’s vast, diverse output allows researchers to apply straightforward filters for synthetic feasibility, streamlining the transition from virtual molecules to lab-ready candidates. Compared to models in the MOSES benchmark, which often yield lower validity and diversity [4], Anyo MolGen’s high uniqueness (>99.0%) and validity ensure a greater proportion of synthesizable hits, accelerating the drug discovery pipeline.
Applications in Drug Discovery
Applying a molecular generator to Anyo Labs toolkit supports multiple stages of drug discovery:
- Novel Lead-Like Hit Generation: As shown in the internal project, the molecular generator produces diverse, synthesizable compounds, providing a rich pool for early-stage screening.
- Hit Identification via Similarity Search: Generated"hits" can be cross-referenced with databases like ChemBL or PubChem to identify molecules with similar properties, while being easily synthesized.
- Hit-to-Lead and Lead Optimization: By providing the model with a seed, Anyo MolGen becomes an analogue generation tool. Applying downstream filtering a pipeline that optimizes molecules for multiple pharmacokinetic properties can be created, refining leads for clinical development.
These applications underscore Anyo's generative AI's role as a comprehensive tool for advancing drug discovery from hit identification to lead optimization.
Looking Ahead: Exploring Chemical Space A forthcoming article, set to be published later this month, will provide a detailed analysis of Anyo MolGen’s ability to explore chemical space, estimated at a minimum of 7.3 × 10^13 unique molecules, with theoretical upper limits surpassing 10^60. This study will quantify the tools diversity, reporting Tanimoto dissimilarity scores up to 0.89 for SMILES and scaffolds, and introduce innovative methods, such as ecological species richness estimators (e.g., Chao1, ACE), to estimate its vast generative capacity.
References
- [1] Reymond, J.-L. (2015). The chemical space project. Accounts of Chemical Research, 48(3), 722–730. https://doi.org/10.1021/ar500432k
- [2] Ruddigkeit, L., et al. (2012). Enumeration of 166 billion organic small molecules in the chemical universe database GDB-17. Journal of Chemical Information and Modeling, 52(11), 2864–2875. https://doi.org/10.1021/ci300415d
- [3] Walters, W. P., & Murcko, M. (2020). Assessing the impact of generative AI on medicinal chemistry. Nature Biotechnology, 38(2), 143–145. https://doi.org/10.1038/s41587-020-0418-2
- [4] Polykovskiy, D., et al. (2020). Molecular sets (MOSES): A benchmarking platform for molecular generation models. Frontiers in Pharmacology, 11, 565644. https://doi.org/10.3389/fphar.2020.565644
- [5] Gómez-Bombarelli, R., et al. (2018). Automatic chemical design using a data-driven continuous representation of molecules. ACS Central Science, 4(2), 268–276. https://doi.org/10.1021/acscentsci.7b00572
- [6] Jin, W., et al. (2018). Junction tree variational autoencoder for molecular graph generation. Proceedings of the 35th International Conference on Machine Learning (PMLR), 80, 2323–2332. http://proceedings.mlr.press/v80/jin18a.html
- [7] Segler, M. H. S., et al. (2018). Generating focused molecule libraries for drug discovery with recurrent neural networks. ACS Central Science, 4(1), 120–131. https://doi.org/10.1021/acscentsci.7b00512
- [8] Mahdizadeh, S. J., & Eriksson, L. A. (2025). iScore: A ML-based scoring function for de novo drug discovery. Journal of Chemical Information and Modeling, 64(7), 2560–2571. https://doi.org/10.1021/acs.jcim.4c02192
- [9] Olivecrona, M., et al. (2017). Molecular de-novo design through deep reinforcement learning. Journal of Cheminformatics, 9, 48.